



FastDFS software introduction
The main functions are: file storage, file synchronization and file access, large capacity and load balancing, mainly used to solve large data storage problems. HDFS in big data also solves a large number of data storage problems. Fast DFS storage files are typically small (4KB-500MB). The number of saved files is relatively large, mostly images. HDFS is Google's file server and a distributed file system in Hadoop. The file data that can be stored is very large and the number of files is very large.
FastDFS software features
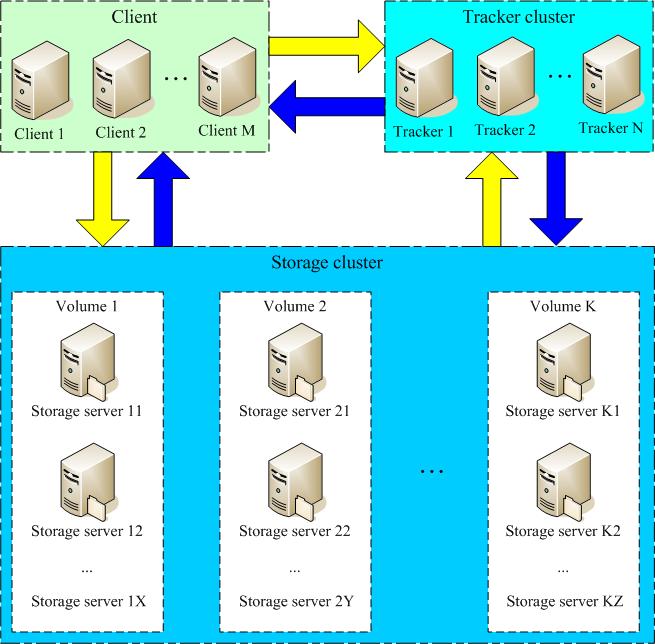
The FastDFS server has two roles: tracker and storage node. The tracker mainly does scheduling work and plays a load balancing role in access.
The storage node stores files and completes all functions of file management: it stores, synchronizes and provides access interfaces. FastDFS also manages the metadata of files. The so-called meta of the file data is the relevant attributes of the file, in the form of key-value pairs (key value), such as: width=1024, where the key is width and the value is 1024. File metadata is a list of file attributes and can contain multiple key-value pairs.
Both trackers and storage nodes can be composed of one or more servers. Servers in both trackers and storage nodes can be added or taken offline at any time without affecting online services. All servers in the tracker are peers and can be increased or decreased at any time based on the pressure on the server.
In order to support large capacity, storage nodes (servers) are organized into volumes (or groups). A storage system consists of one or more volumes. Files between volumes are independent of each other. The sum of the file capacities of all volumes is the file capacity of the entire storage system. A volume can be composed of one or more storage servers. The files in the storage servers under a volume are all the same. Multiple storage servers in the volume play the role of redundant backup and load balancing.
When adding a server to the volume, synchronization of existing files is automatically completed by the system. After the synchronization is completed, the system automatically switches the newly added server to provide online services.
When storage space is insufficient or about to be exhausted, volumes can be added dynamically. Simply add one or more servers and configure them as a new volume, thereby expanding the capacity of the storage system.
The file identification in FastDFS is divided into two parts: the volume name and the file name, both of which are indispensable.
FastDFS usage instructions
Upload interactive process
1. The client asks the tracker for the storage uploaded to, no additional parameters are required;
2. The tracker returns an available storage;
3. The client communicates directly with the storage to complete the file upload.
Download interactive process
1. The client asks the tracker for the storage of the downloaded file, and the parameter is the file identifier (volume name and file name);
2. The tracker returns an available storage;
3. The client communicates directly with the storage to complete the file download.
It should be noted that the client is the caller using the FastDFS service, and the client should also be a server. Its calls to tracker and storage are all inter-server calls.
FastDFS update log
1. Optimize content
2. The details are more outstanding and the bugs are gone.
Huajun editor recommends:
Say goodbye to junk software, FastDFS is a green and safe software, the editor has personally tested it! Our Huajun Software Park serves you wholeheartedly. There are alsoDebian For Linux,COSCO Kirin iAudit operation and maintenance audit system centos7 installation package,Nut Cloud (64bit) For Linux,7-Zip,WPS Office For Linux DEB, available for you to download!



























Useful
Useful
Useful