
-
Regular expression testing tool RegexTester
- Size: 0.04M
- Language: Simplified Chinese
- category: Programming controls
- System: Win All






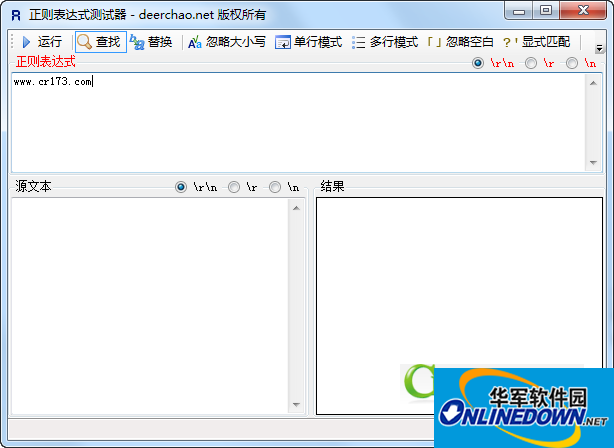
Regextester is a regular expression tester that supports single-line mode, multi-line mode, and classic window design. This tool allows you to test and analyze regular expressions. Regular expressions are commonly used for two tasks: 1. validation, 2. search/replace. When used for verification, it is usually necessary to add ^ and $ before and after to match the entire string to be verified; whether to add this limit when searching/replacing depends on the search requirements.
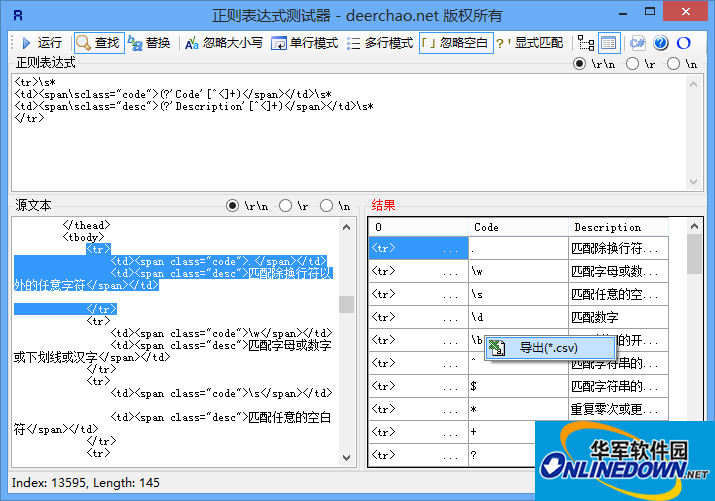
Function introduction:
Supports matching using only the selected part of the expression
Supports two result viewing methods: tree and table
When a tree node or cell is selected, the corresponding part of the source text is automatically selected.
Table content can be exported to a csv file (in table mode, right-click the result and select "Export (*.csv)" in the pop-up menu)
Support dragging in files as matching source text
Supports shortcut key operations (F5 to run, F4 to switch query and replacement mode, F6 to switch result display mode, F2 to copy code, F8 to switch focus)
Supports generating and copying C# code to the system clipboard
Supports multiple options such as ignoring case, single-line mode, multi-line mode, ignoring whitespace, explicit matching, etc.
Automatically load the last set of data run before the last shutdown
Can parse C# code similar to new Regex("abc", RegexOptions.Singleline | RegexOptions.Multiline) format
Pre-search for regular expressions:
Regular expression: (?<=src=").*?(?=") "Indicates escape, that is, double quotes"
Among them (?<=) is reverse pre-search, which means that the string to be matched must be preceded by scr="
(?=) is a forward pre-search, which means that the string to be matched must be followed by "
.*? indicates the part to be matched
for example:
Formal expression: (?<=src=").*?(?=")
Text to be tested: <img src="/UploadFiles/image/20140304/20140304094318_2971.png" alt="RegexTester" />
Then after executing this regular expression, you can extract /UploadFiles/image/20140304/20140304094318_2971.png
Getting Started with Regular Expressions:
b matches the beginning or end of a word
* means repeating 0 zero or more times
? means repeat 0 or 1 times
+ means repeat 1 or more times
{n} Repeat n times
{n,} repeated n or more times
{n,m} repeated n to m times
. represents any character except newline characters
.* together means any number of characters that do not include newlines
d represents a single digit (0, or 1, or 2...or 9)
s represents any whitespace character, including spaces, tabs, newlines, and Chinese full-width spaces.
w matches letters or numbers or underscores or Chinese characters
^ matches the beginning of a string
$matches the end of the string
Indicates escape, such as "means", (means (
[] represents a range. For example, [.?!] matches punctuation marks (. or? or!). The meaning represented by [0-9] is exactly the same as d: it represents a 1-digit number; similarly [a-z0-9A -Z_] is also completely equivalent to w (if only English is considered)
| represents a branch (or), such as d{5}-d{4}|d{5}. This expression is used to match zip codes in the United States. The rule for U.S. zip codes is 5 digits, or 9 digits separated by hyphens. The reason why this example is given is because it can illustrate a problem: when using branch conditions, pay attention to the order of each condition. If you change it to d{5}|d{5}-d{4}, then only 5-digit zip codes (and the first 5 digits of 9-digit zip codes) will be matched. The reason is that when matching branch conditions, each condition will be tested from left to right. If a certain branch is met, other conditions will not be considered.
We've already mentioned how to repeat a single character (just add a qualifier after the character); but what if you want to repeat multiple characters? You can use parentheses to specify a subexpression (also called grouping), and then you can specify the number of repetitions of this subexpression. You can also perform other operations on the subexpression (will be introduced later).
(d{1,3}.){3}d{1,3} is a simple IP address matching expression. To understand this expression, analyze it in the following order: d{1,3} matches a number from 1 to 3 digits, (d{1,3}.){3} matches a three-digit number plus a period (this The whole is this group) repeated three times, and finally a one to three-digit number (d{1,3}) is added.
Each number in the IP address cannot be greater than 255. People often ask me, is the number 01.02.03.04 with a 0 in front of it a correct IP address? The answer is: Yes, the numbers in the IP address can contain leading numbers. 0 (leading zeroes).
Unfortunately, it will also match the impossible IP address 256.300.888.999. If you can use arithmetic comparison, you may be able to solve this problem simply, but regular expressions do not provide any mathematical functions, so you can only use lengthy grouping, selection, and character classes to describe a correct IP address:( (2[0-4]d|25[0-5]|[01]?dd?).){3}(2[0-4]d|25[0-5]|[01]?dd? ).
The key to understanding this expression is to understand 2[0-4]d|25[0-5]|[01]?dd?
W matches any character that is not a letter, number, underscore, or Chinese character
S matches any character that is not whitespace
D matches any non-digit character
B matches a position that is not the beginning or end of the word
[^x] matches any character except x
[^aeiou] matches any character except the letters aeiou
Example: S+ matches a string that does not contain whitespace characters.
<a[^>]+> matches a string starting with a enclosed in angle brackets.
Version: 1.0.9 Green version | Update time: 2024-11-01
Similar recommendations







Latest updates





How to log in to 360 Secure Browser? -How to log in to 360 secure browser
How to turn off footsteps in cs1.6-How to turn off footsteps in cs1.6
How to delete robots in cs1.6-How to delete robots in cs1.6
How to buy weapons in cs1.6-How to buy weapons in cs1.6
How to install plug-in for 360 Secure Browser? -How to install plug-ins for 360 Secure Browser
How to buy bullets in cs1.6-How to buy bullets in cs1.6
How to clear the cache of 360 Secure Browser? -How to clear the cache of 360 Safe Browser
How to upgrade 360 Secure Browser? -How to upgrade the version of 360 Secure Browser
How to switch accounts to log in to iQiyi? -How to log in to iQiyi account switching account
Regular expression testing tool RegexTester review
-
1st floor Huajun netizen 2019-08-06 23:02:54The regular expression testing tool RegexTester is very useful, thank you! !
-
2nd floor Huajun netizen 2019-10-29 09:25:41RegexTester, a regular expression testing tool, is not bad. It downloads very quickly. I would like to give you a good review!
-
3rd floor Huajun netizen 2018-02-24 21:56:18RegexTester, the regular expression testing tool, hopes to get better and better, come on!
Recommended products







- Diablo game tool collection
- Group purchasing software collection area
- p2p seed search artifact download-P2P seed search artifact special topic
- adobe software encyclopedia - adobe full range of software downloads - adobe software downloads
- Safe Internet Encyclopedia
- Browser PC version download-browser download collection
- Diablo 3 game collection
- Anxin Quote Software
- Which Key Wizard software is better? Key Wizard software collection



