
-
ictclas
- Size: 64.32M
- Language: Simplified Chinese
- Category: Liberal Arts Tools
- System: Win7/XP/2000/2003/Vista






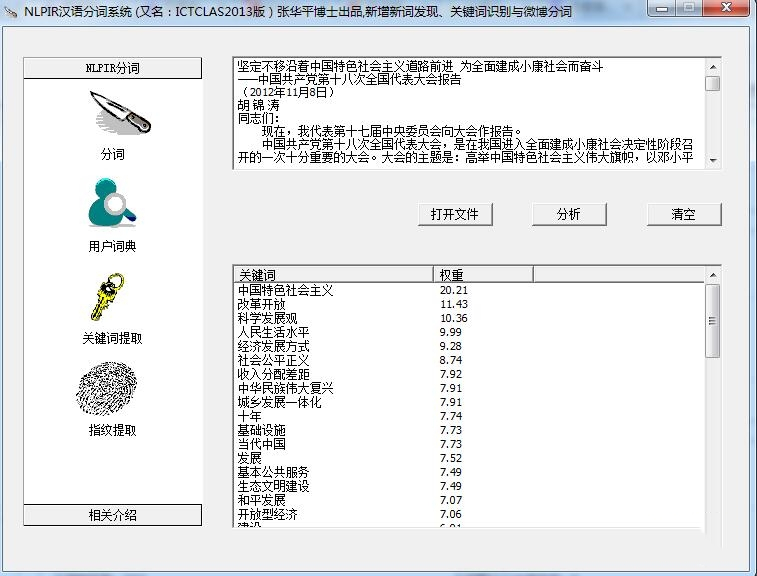
The official version of ictclas is a powerful word segmentation system. The latest version of ictclas supports Chinese word segmentation, part-of-speech tagging, named entity recognition, new word recognition, user dictionaries and other functions, which can help users conduct analysis and research on Chinese language morphology. The ictclas software also provides users with functions such as part-of-speech standards, keyword extraction, and interface expansion to meet the needs of different users.
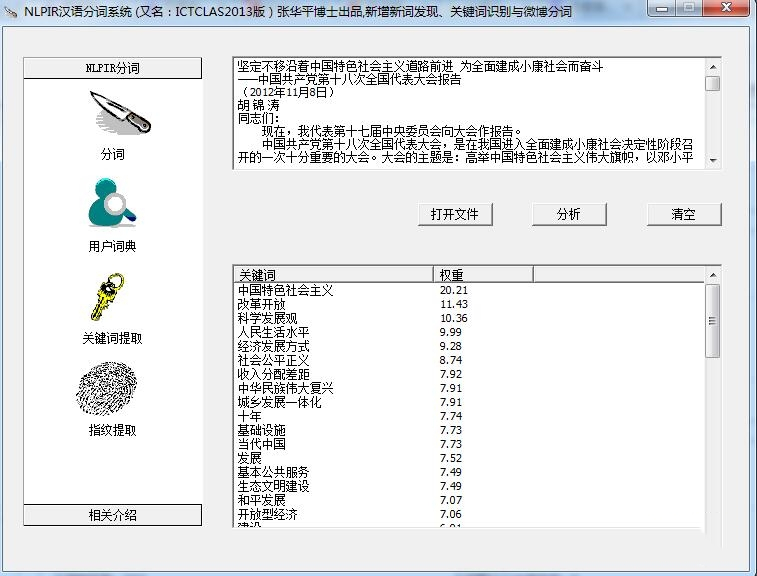
ictclas software introduction
Based on years of research work, the Institute of Computing Technology of the Chinese Academy of Sciences has developed the Chinese Lexical Analysis System ICTCLAS (Institute of Computing Technology, Chinese Lexical Analysis System). Its main functions include Chinese word segmentation; part-of-speech tagging; named entity recognition; new word recognition; and it also supports user dictionaries. We have carefully built it for five years and upgraded the kernel 7 times. Currently, it has been upgraded to ICTCLAS2009 user dictionary interface extension. Users can dynamically add and delete words in the user dictionary and adjust the effect of word segmentation. Improved the flexibility of user dictionary usage.
Since 2009, ICTCLAS lexical analysis system has been renamed NLPIR word segmentation system in order to distinguish it from previous work and promote the NLPIR natural language processing and information retrieval sharing platform. Dr. Zhang Huaping has worked hard to build it for more than ten years and upgraded the core more than ten times. He has won the first prize of the Qian Weichang Chinese Information Processing Science and Technology Award in 2010, the overall first place in the International SIGHAN Word Segmentation Competition in 2003, and the overall first place in the domestic 973 evaluation in 2002. The number of global users has exceeded 300,000, including enterprises such as China Mobile, Huawei, China Sou, 3721, NEC, China Business Network, Silicon Valley Dynamics, Yunnan Daily, and institutions such as Tsinghua University, Xinjiang University, South China Institute of Technology, and the University of Massachusetts: At the same time, ICTCLAS has been widely reported by many media such as "Science Times", "People's Daily" Overseas Edition, "Science and Technology Daily" and other media. You can visit Google to learn more about the application of ICTCLAS.
ictclas software functions
1. Fingerprint extraction
Based on the content, structure, and relationship between words of the article, the semantic fingerprint that can represent the article is analyzed and represented by a numerical sequence.
2. The word segmentation granularity is adjustable
You can control the granularity of word segmentation results. The shared version provides two word segmentation granularities, standard granularity and coarse granularity, to meet the needs of different users.
3. User dictionary interface extension
Users can dynamically add and delete words in the user dictionary and adjust the effect of word segmentation. Improved the flexibility of user dictionary usage.
4. Enhanced part-of-speech tagging function
There are multiple annotation levels to choose from. The annotation levels available for the system include: Institute of Computing Technology first-level annotation level, Institute of Computing Technology second-level annotation set, Peking University first-level annotation set, and Peking University second-level annotation set.
5. Keyword extraction
Automatically extract several words or phrases that can well represent the topic of the document. Keyword extraction technology is widely used in various intelligent text information processing fields such as information retrieval, text classification/clustering, information filtering, document summarization, etc., and has great application value.
6. New word discovery and adaptive word segmentation function
From longer text content, new feature languages are automatically discovered based on information cross-entropy, and the language probability distribution model of the test corpus is adaptively tested to achieve adaptive word segmentation.
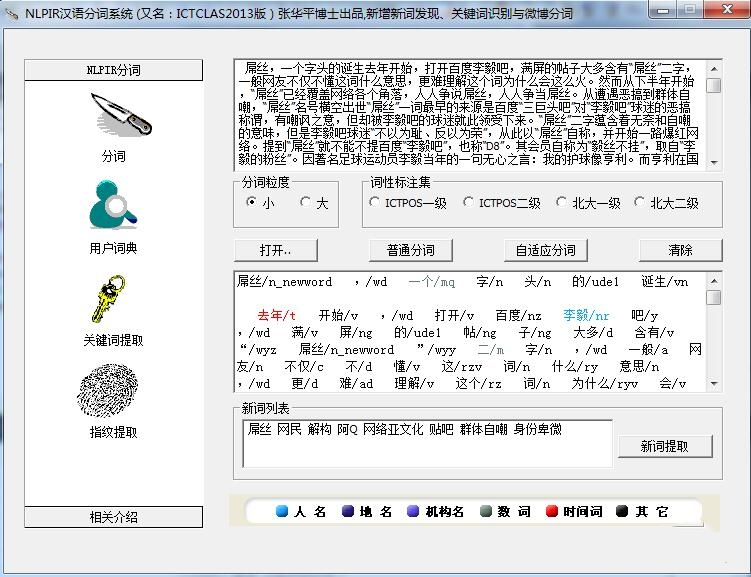
ictclas software advantages
1. Public evaluation by domestic and international authorities, recognition by 30,000 customers
For commercial purposes, some companies close their doors and self-test, claiming that the accuracy is 99.50%, without introducing the test environment and test methods. It is not surprising that the accuracy of closed tests or small-scale open tests is 100%. ICTCLAS1.0 won first place in the evaluation organized by the domestic 973 expert group, and ICTCLAS2.0 won multiple first places in the evaluation organized by SigHan, the first international Chinese processing research institution. For details, see the system evaluation section. These are the results of large-scale on-site open testing conducted by authoritative organizations and are authentic and credible.
ICTCLAS has issued more than 30,000 authorizations to domestic and foreign enterprises and academic institutions, including 3721, NEC, China Business Network, Silicon Valley Power, Yunnan Daily and other enterprises, Xinjiang University, Tsinghua University, South China Institute of Technology, University of Massachusetts; at the same time, ICTCLAS has been widely reported by the Science Times, People's Daily Overseas Edition, Science and Technology Daily and other media. You can visit Google to learn more about the application of ICTCLAS.
2. Optimum overall performance
Whether the word segmentation system can meet practical requirements mainly depends on two factors: word segmentation accuracy and analysis speed. The two restrict each other and are difficult to balance. Most systems tend to fall into the dilemma of "fast but not accurate, accurate but not fast". We have developed the perfect PDAT large-scale knowledge base management technology, which has made a major breakthrough between high speed and high accuracy. This technology can manage millions of dictionary knowledge bases, and a single machine can query 1 million entries per second, while the memory consumption is less than 1.5 times the size of the knowledge base. Based on this technology, ICTCLAS3.0 has a word segmentation speed of 996KB/s on a single machine, a word segmentation accuracy of 98.45%, an API of no more than 200KB, and various dictionary data after compression of less than 3M. It is currently the best Chinese lexical analyzer in the world.
3. Unified linguistic computing theoretical framework
Chinese word segmentation involves many factors such as Chinese word segmentation, undefined word recognition, part-of-speech tagging, and language special cases. Most systems lack a unified processing method and often use loosely coupled module combinations. The final model cannot accurately and effectively express the vastly different language phenomena. ICTCLAS uses a cascading hidden Markov model (Hierarchical Hidden Markov Model), unifies all aspects of Chinese lexical analysis into a complete theoretical framework to achieve the best overall effect. Relevant theoretical research has been published in top international conferences and magazines, confirming the advancement of the model both theoretically and practically.
4. Comprehensive support for application development in various environments
ICTCLAS is all written in C/C++, supports Linux, FreeBSD and Windows series operating systems, and supports mainstream development languages such as C/C++/C#/Delphi/Java.
5. Change according to needs and tailor-made
All functional modules can be disassembled and assembled. ICTCLAS has GB2312 and BIG5 versions, which can handle simplified and traditional Chinese respectively; it supports currently widely recognized word segmentation and part-of-speech standards, including the calculation of part-of-speech annotation set ICTPOS3.0, Peking University standards, Binzhou University standards, National Language Commission standards, Taiwan's "Academia Sinica", Hong Kong "City University"; users can directly customize the output part-of-speech standards and define the output format; users can customize a word segmentation system that suits them based on their own needs.
ictclas update log
1. Optimized some functions
2. Solved many unbearable bugs
Huajun editor recommends:
Looking around, there are software similar to this software everywhere on the Internet. If you are not used to this software, you might as well try Yizibo, Yizibo, .NET and other software. I hope you like it!
Version: 2016 official version | Update time: 2024-12-23
Similar recommendations





Latest updates





How to set up automatic saving in autocad-How to set up automatic saving in autocad
How to export pdf from autocad-How to export pdf from autocad
How to draw dotted lines in autocad-How to draw dotted lines in autocad
How to enable hardware acceleration in autocad-How to enable hardware acceleration in autocad
How to make curved text in coreldraw - How to make curved text in coreldraw
How to make special effect fonts in coreldraw - How to make special effect fonts in coreldraw
How to split text in coreldraw - How to split text in coreldraw
How does coreldraw manage multi-page typesetting - How does coreldraw manage multi-page typesetting?
How to create perspective effect in coreldraw - How to create perspective effect in coreldraw
ictclas comments
-
1st floor Huajun netizen 2021-10-05 07:47:25ictclas is awesome! 100 million likes! ! !
-
2nd floor Huajun netizen 2011-10-06 15:29:11The overall feeling of ictclas is good and I am quite satisfied with it. The installation and operation are very smooth! It went very smoothly following the installation step-by-step instructions!
-
3rd floor Huajun netizen 2009-04-17 01:51:38ictclas is not bad, the download is very fast, I give you a good review!
Recommended products
-

PEP version of primary school Chinese language teaching courseware for the first grade of the first volume of the complete text
-

Complete collection of rhymes
-

Master of Calligraphy Practice Methods
-

Three Hundred Tang Poems
-

pen god
-

Electronic Xinhua Dictionary
-

Yixuetang fast reading training system
-

Ancient poems and essays from past dynasties
-

Lighthouse online answer questions
-
Paper latent search
- Diablo game tool collection
- Group purchasing software collection area
- p2p seed search artifact download-P2P seed search artifact special topic
- adobe software encyclopedia - adobe full range of software downloads - adobe software downloads
- Safe Internet Encyclopedia
- Browser PC version download-browser download collection
- Diablo 3 game collection
- Anxin Quote Software
- Which Key Wizard software is better? Key Wizard software collection



